Welcome to my portfolio!

Data Scientist/Analyst with experiences in USA, Japan, and Singapore.
Welcome to my data science portfolio. This portfolio contains my work on data science on Kaggle, or for my other courses and job interviews.
Predicting Daily Sales of Stores with four different TSA models.
Published: 4th-Dec-2023
Updated: 25th-Jun-2025
This is the code repository for the Jupyter Notebook which was used to perform time-series experiments.
Four different time-serie models were being experimented: 1) ARIMA, 2) VARMA, 3)XGBoost, 4)VARMA-XGBoost
This code was used to support my candidacy for my Master’s of Science in Machine Learning and Artificial Intelligence.
Link to Github repository for Master’s project
 .
.
Predicting Daily Sales of Stores - Time Series Analysis.
Published: 24th-Apr-2023
Updated: 24th-Apr-2023
This project aims to predict the daily sales of stores through time series analysis. There will be two approaches to this project.
The first project (completed 2nd-Feb-2023) was aimed at creating a time series model through VARMA and VARMAX models.
The second ongoing project wil be aiming at creating a time series model through Deepl Learning models
Link to Github repository for first project
 .
.
Image obtained from Pixabay: https://pixabay.com/photos/hangers-clothing-shopping-market-1850082/
Part of Speech Tagging for Medical Treatment
Published: 17th-Aug-2022
Updated: 17th-Aug-2022
This project aims to build a build an algorithm to map the diseases and their respective treatment through building a custom NER to get the list of diseases and their treatment from the dataset. This will allow a web platform, ‘BeHealthy’, to allow doctors to list their services and manage patient interactions and provide services for patients such as booking interactions with doctors and ordering medicines online.
Link to Github repository for first project
 .
.
Image obtained from Pixabay: https://cdn.pixabay.com/photo/2014/12/10/20/48/laboratory-563423_960_720.jpg
Gesture Recognition using a 3D CNN or a CNN/RNN layer.
Published: 13th-Jul-2022
Updated: 13th-Jul-2022
This project aims to build a 3D CNN or a CNN/RNN in order to perform gesture recognition on video data (but in this case, video data are being reformatted into moving, still pictures). Best results was achieved when transfer learning was used in which GRU model was built on top of Google Inception v3.
 .
.
Image obtained from MarkTechPost: https://www.marktechpost.com/wp-content/uploads/2021/12/JEI_30_6_063026_f009.png
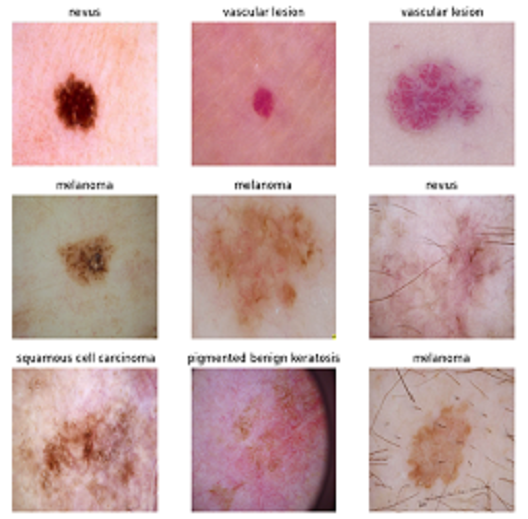
Detecting Melanoma through a CNN model.
Published: 15th-Jun-2022
Updated: 15th-Jun-2022
This project aims to build a CNN model which uses photographs of moles and different types of skin pigmentations to identify melanoma. Melanoma is a type of cancer that can be deadly if not detected early. It accounts for 75% of skin cancer deaths. Three CNN models were being developed and class was rebalanced to achieve greater recall scores.
 .
.
Telecom Churn Case Study
Published: 10th-May-2022
Updated: 10th-May-2022
This project aims to build several Machine Learning models (with a Logistics Regression model as the baseline, build a Logistics Regression model with Regularization, Random Forest model, XGBoost Model) in order to predict whether customers from a telecom will churn. The metric that determines the strength of our model is Recall metric.
 .
.
Image obtained from HEAVY.AI: https://assets-global.website-files.com/620d42e86cb8ecb3f739e579/621da98e3868804479cdbbac_AdobeStock_361596081%20copy.jpeg
Predicing House Prices in Australia
Published: 6th-Apr-2022
Updated: 6th-Apr-2022
Surprise Housing is looking to invest in the Australian market, but being new to Australia, does not know which variables are significant in predicting the price of a house, and how well those variables describe the price of a house. Model used was a Multivariate Logistics Regression with Lasso Regularization.
 .
.
Image obtained from Archistar: https://www.archistar.ai/wp-content/uploads/2022/03/Determining-Future-House-Prices-And-Their-Impact-on-Property-Development.jpg
Bike Sharing in the United States
Published: 8th-Feb-2022
Updated: 8th-Feb-2022
This project aims to help US bike-sharing company, BoomBikes, identify the factors (variables) affect the demand of shared bikes in the US market. The aims of this project is to identify the variables which are significant in predicting the demand for shared bikes, and how well do these variables describe the bike demand for BoomBikes.
 .
.
Image obtained from Wikipedia: https://upload.wikimedia.org/wikipedia/commons/thumb/8/87/002141_Bicycle-sharing_systems-Sweden.jpg/1200px-00_2141_Bicycle-sharing_systems-_Sweden.jpg
Lending Club EDA
Published: 5th-Jan-2022
Updated: 5th-Jan-2022
In this case study which only utilizes Exploratory Data Analysis to identify common types of risks found in consumer finance companies lending loans: If the applicant is likely to repay the loan, then not approving the loan results in a loss of business to the company, and if the applicant is not likely to repay the loan, i.e. he/she is likely to default, then approving the loan may lead to a financial loss for the company
 .
.
Image obtained from Lending Club: https://investorjunkie.com/wp-content/uploads/2015/05/lending-club-2.png
Latent Dirichlet allocation on job listings
Published: 30th-Sept-2021
Updated: 30th-Sep-2021
Believing that job listings all contains certain keywords which are specifically written for the profession, in this project, I attempted to use Latent Dirichlet allocation (LDA) to extract the common keywords and themes associated with each job listing, so that we can use an unsupervised approach in classifying each of the job listings into each various themes.
 .
.
Tableau Portfolio on taxi data in Chicago
Published: 5th-Aug-2021
Updated: 5th-Aug-2021
In this project, I used the open data base from Google BigQuery in which I analyzed the market share and market trend for taxi companies in Chicago, by comparing the yearly market share and trends of the individual taxi companies, and the impact of lockdown from the pandemic has had on the taxi companies. I have found the taxi companies have been merging to consolidate resources in these challenging times with much fewer companies today in Chicago than in previous years.
 .
.
Real or Not NLP with Disaster Tweets
Published: 21st-Mar-2020
A Kaggle Data Science project in which I used feature engineering to pick out features, such as number of punctuation, sentence length etc., in order to build a model in which disaster and non-disaster tweets can be separated. Achieved a Training accuracy of 79% and a Test accuracy of 76% through the use of feature engineering.
 .
.
Kaggle Competition Data Science for Good, City of Los Angeles
A Kaggle Data Science project in which we tried to find if the job listing contains any types of biasness. We first parsed the job listings into a dataframe before applying text analytics, in which we attempted to find which job listing contains more masculine words, and which job listing contains more feminine words.